Your AI Agent Doesn't Need Perfect Data. It Needs to Know What's in the Warehouse.

There is a growing consensus in the data industry that goes something like this: AI agents connected to your warehouse can write perfect SQL but produce wrong business conclusions. Therefore, we need perfect governance. Clean lineage. Agreed ownership. A semantic layer with interpretation contracts for every KPI. Data contracts between every producer and consumer.
Then, and only then, can you safely let an AI agent anywhere near your warehouse.
This week, I came across the final boss of this idea: a new architectural layer, a “Semantic API,” where every metric is formalised as an executable contract with interpretation rules, comparison boundaries, and permitted actions. The agent doesn’t query tables; it calls functions. Meaning is delivered, not inferred.
The argument is elegant. For most companies, it is also advice for step twelve when they are stuck on step two.
The Problem Is Real
Before dismissing the vision, it is worth acknowledging what it gets right. When you ask an AI agent to show customer churn for last month, it will find an activity date, apply a time window, and count users who stopped appearing. The SQL will be valid. The number will be wrong. Not because the model hallucinated, but because “churn” inside your company means something specific: it involves payment status, subscription state, refund handling, a confirmation lag, maybe a cohort exclusion that someone decided on in a meeting eighteen months ago and never wrote down. The agent picked a plausible definition. The business uses an agreed one. The gap between the two is where trust goes to die.
This is a genuine problem, and anyone who has watched a stakeholder lose confidence in an AI-generated report because the revenue number was off by a factor of three will feel it viscerally. The perfectionism crowd is right that meaning needs to live somewhere outside of people's heads.
Where they lose the thread (in our humble opinion 😇) is in the prescription. Not just the Semantic API, but the entire mindset that treats pristine infrastructure as a prerequisite for doing anything with AI at all. The semantic layer is the most ambitious expression of this thinking, but the pattern is everywhere: you must govern before you document, document before you deploy, deploy only once everything is clean.
Crawl Before You Walk, Before You Run
The data industry has a long history of reaching for architectural elegance before solving operational basics. Data mesh was supposed to decentralize ownership, but most teams adopted the vocabulary without the organisational change. Data contracts were supposed to formalise producer-consumer agreements, but producers could not even describe what they produced. The Semantic API imagines a world where every metric exists as a callable function, where get_recognized_revenue(period, segment) returns not just a number but an interpretation contract that the agent cannot deviate from. No ambiguity. No alternative readings. Meaning is fixed, executable, and machine-enforceable.
This is a beautiful idea for companies that have already documented their data, already agreed on metric definitions across departments, already mapped their table relationships, already reconciled the three different versions of the customer table that somehow coexist in production.
For everyone else, which is nearly everyone (at least everyone we’re talking to), the warehouse is still full of tables that nobody understands. Somewhere in yours right now, there is a column called col_b that contains a number. Is it a price? A quantity? An ID? Nobody documented it. The person who created it left the company. Three downstream models depend on it. The catalog you bought to solve this problem has been sitting empty since procurement signed the contract.
You cannot formalise the meaning of a metric that nobody has defined yet. You cannot build interpretation contracts on top of tables that nobody understands. Perfect governance is the roof. The Semantic API is solar panel tiling. Most companies have not poured the foundation.
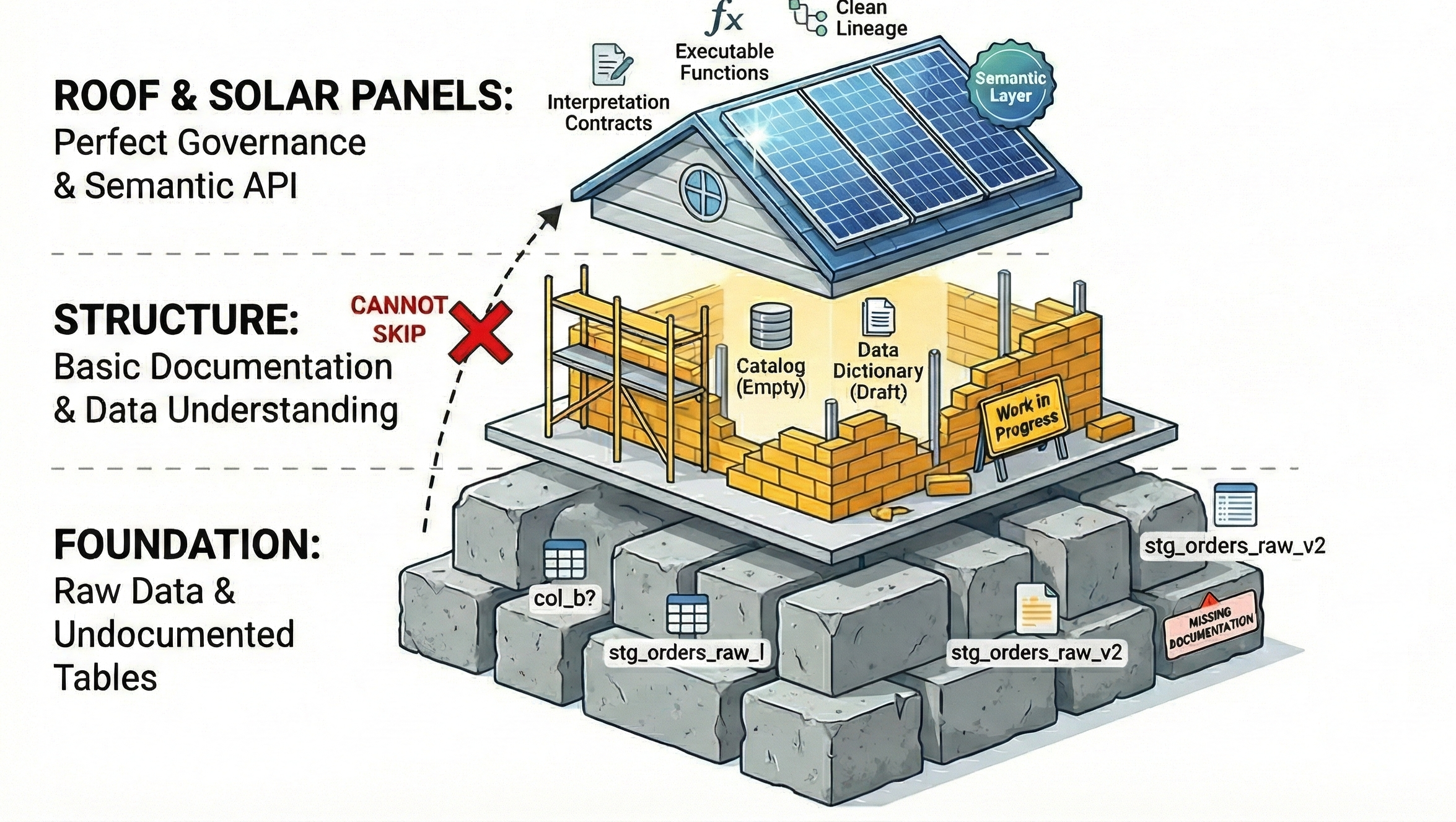
What Is Actually Working
Here is what the perfection-first crowd misses: data teams are not waiting for the foundation to be poured. They are already getting value from AI on messy, imperfect, under-documented warehouses. Not by deploying autonomous agents that stop campaigns and adjust forecasts. By doing something much simpler and much more immediately useful: using AI to accelerate the data team's own BI work.
This is not self-service analytics for the whole company. That does require more trust infrastructure. This is a data analyst using an AI agent to explore the warehouse, write queries, check metric logic, and answer the kinds of questions that used to eat two hours of manual SQL writing and Slack archaeology. “Which table has the canonical revenue number?” “What does this staging table actually contain?” “Why do these two dashboards show different customer counts?”
Data teams working this way are recovering five to ten hours per analyst per week. Not because the AI is perfect, but because the AI is good enough for a skilled human to work with. The analyst still validates. The analyst still catches errors. But starting from a plausible answer instead of a blank query editor changes the velocity of everything.
If the agent knows which revenue table is canonical and which is a deprecated staging artifact, it will use the right one. If it knows that fct_orders contains verified transactions joined with payments, and that stg_orders_raw_v2 is an intermediate table that should never be queried directly, it will not confuse them. If it understands that col_a in that cryptically named table is actually a product SKU and col_b is a price in euros, it can reason about the data intelligently instead of guessing.
This is not a Semantic API. It is documentation. And the reason companies don’t have it is not that they don’t understand its value and that producing it has always been brutally manual. Every documentation sprint starts with enthusiasm and dies within weeks, because the people who understand the data are the same people drowning in ad-hoc requests, and there are never enough hours.
The Flywheel Nobody Planned For
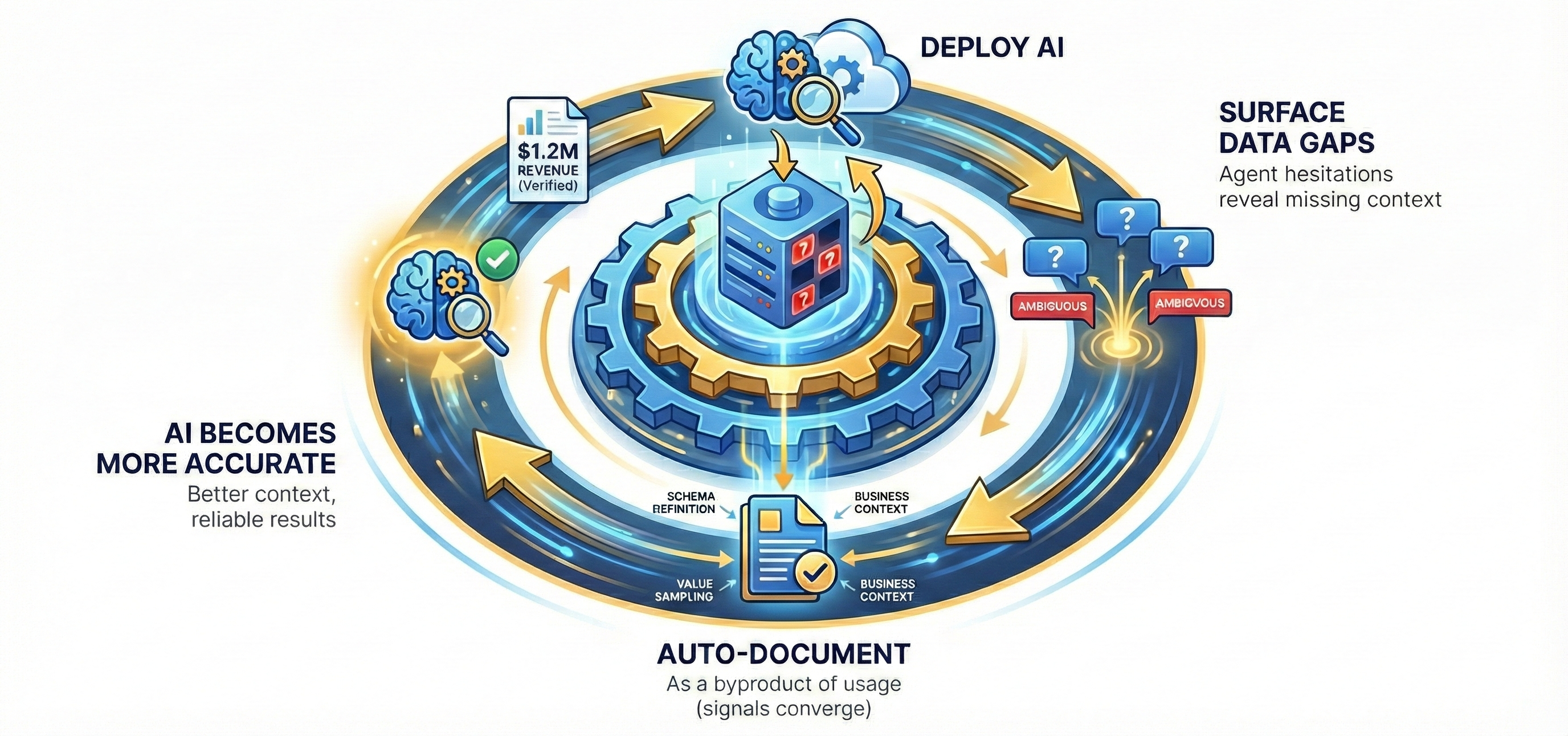
Something interesting happens when data teams start using AI on their warehouse without waiting for perfect documentation. The AI's questions reveal the gaps. Every time the agent hesitates on which table is canonical, every time it flags an ambiguous column name, every time it asks whether stg_orders_raw_v2 is current or deprecated, it is producing a map of what the warehouse is missing.
Capture those signals, and documentation stops being a project that dies in three weeks. It becomes a byproduct of usage. The warehouse gets more understandable over time, not because someone ran a documentation sprint, but because the act of querying it with AI continuously surfaces what needs to be named, described, and clarified.
This is the flywheel that the perfection-first thinking cannot account for. It imagines documentation as a prerequisite for AI. In practice, AI is becoming the fastest path to documentation.
Consider what it takes to understand a single table in a warehouse. You need to profile its columns statistically, to know the distributions, the outliers, the ranges. You need to sample actual values, because a column called col_a that contains “Van Rysel RCR” is telling you something that the schema never will: this is product data, probably retail, probably Decathlon. You need to cross-reference against any existing documentation, even stale documentation, because a legacy description that says “product list” while the actual data has evolved into a live pricing master is information in itself, the delta between what people think and what is true. You need to map relationships across tables, because a 98.5% key match between t.sku and stg.col_a reveals a join that no one documented. And you need business context, the kind of real-world knowledge that connects raw values to actual meaning.
No single signal is sufficient. But when you converge five of them (statistical profiling, smart sampling, existing catalog reconciliation, cross-table relationship detection, and business context inference) you can auto-generate documentation that is accurate enough to be useful immediately.
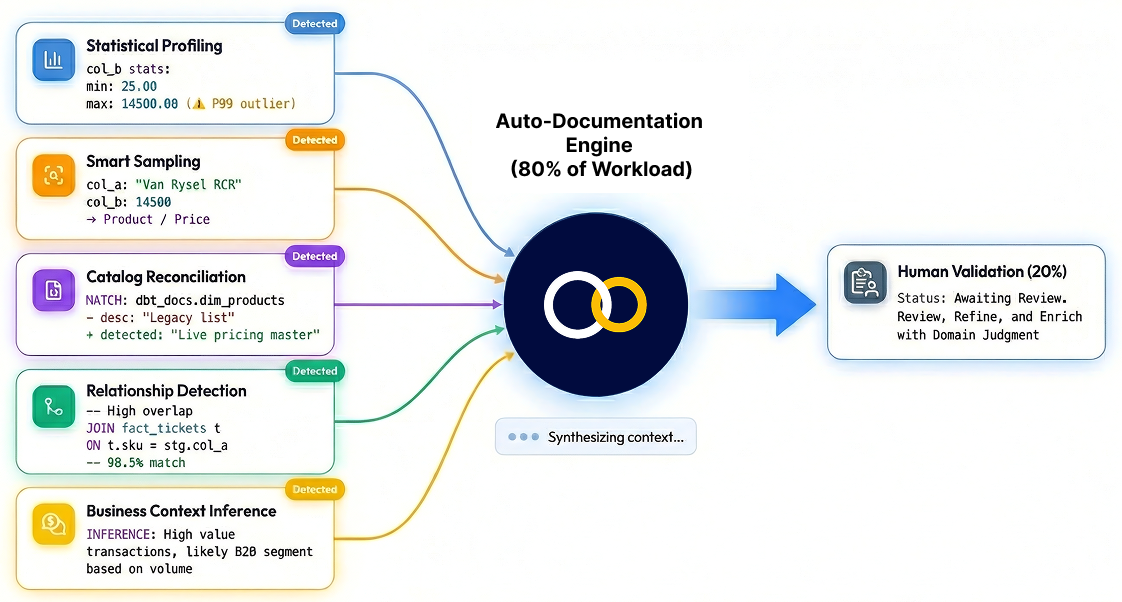
It is also detailed enough to serve as the foundation for everything that comes after, including, eventually, the interpretation contracts the Semantic API crowd dreams about.
Humans stay in the loop. Not to do the work from scratch, but to validate, correct, and enrich. The ratio flips: instead of humans producing 100% of documentation (and therefore producing almost none), the system handles roughly 80% and humans review the 20% that requires domain judgment. The data team’s intelligence goes toward the hard problems, not the mechanical ones.
The Right Sequence
The industry keeps presenting a linear path: govern, then document, then deploy AI. The teams that are actually getting results have discovered the path is circular. Deploy AI with the right tools, even on messy data, even just for the data team. Let it surface the gaps. Use those gaps to build documentation. Let better documentation make the AI more accurate. Repeat.
You do not need a semantic layer to start. You do not need every metric formalised as an executable function. You need a warehouse, an AI that can read it, and a data team willing to validate what comes back.
The semantic layer, the governance framework, the interpretation contracts: these are reasonable destinations. Eventually, for your most critical metrics, you will want formal definitions. Start with the five numbers your CEO looks at every Monday. Define what they mean. Define when they can be compared. Define what constitutes a normal range. Build outward from there.
But do not let the destination prevent the departure.
What Lingers
There is something almost Borgesian about the situation. We built warehouses to store all the data, and now we discover that the data, without meaning, is just noise. We built AI agents to interpret the noise, and they interpret it confidently, fluently, and wrong. The missing piece was never intelligence. It was always knowledge: the quiet, unglamorous, deeply human work of saying what things are and what they mean.
The companies that will deploy AI on their data successfully are not the ones with the most sophisticated interpretation engines or the most perfect governance frameworks. They are the ones that started before they felt ready, learned from what broke, and documented their warehouse while using it, not before.
The bar for starting is lower than the industry admits. The cost of waiting is higher than most teams realise.